점근론을 사용해 코드 성능을 표현해 봅시다.
감으로 때려 맞추는게 아닌, 수학적이고 직관적인 방법으로 어떤 알고리즘이 더 효율적인지 분석하자.
포스트 목표
- 코드 효율성을 측정하는 방법: 시간 측정과 모델링
- 점근적 행동이 무엇인가: 포물선 vs 직선
- 코드 효율성 표기 방법: Cost Model vs Big Theta
코드 효율성을 측정하는 방법
개발자라면 작성한 코드가 효율적으로 실행되도록 고민해야 한다. 코드가 효율적이기 위해선 두가지 비용을 고려해야 한다. 첫째는 프로그래밍 비용이다. 프로그램을 개발하는데 소요되는 시간이다. 그리고 작성된 프로그램을 수정하거나 유지보수 하는데 드는 비용도 포함된다. 두번째는 실행비용이다. 코드가 실행되는데 소요되는 시간이다. 그리고 코드가 필요로 하는 메모리의 양이다.
코드 효율성: 예시
문제: 정렬된 Array가 주어졌을 때, 중복된 요소를 찾아라.

위와 같은 어레이가 주어졌을 때 어떻게 결과물을 찾아볼 수 있을까? 가장 직관적이고 단순한 방법으로는, 가장 첫번째 요소부터 시작해서 하나씩 비교해나갈 수 있다. (-3, -1)을 비교하고, (-3, 2)를 비교하고, (-3, 4)를 비교하고 … (4, 8) 까지 비교를 하는 방식이다. 이 방법은 간편하지만, 사실 비효율적인 알고리즘이다.
효율적인 알고리즘을 고민해본다면, 어레이가 정렬되었다는 사실을 활용할 수 있다. 인덱스 i + 1에 위치한 요소는 무조건 인덱스 i에 위치한 요소보다 크거나 작다. 따라서 (-3, -1)을 비교하고 (-1, 2)를 비교하고, (2, 4) 를 비교하는 식으로 진행하면 된다. 조금 더 수학적으로 풀면 A[i] 와 A[i + 1] 을 비교하고, 마지막 요소까지 조회한다면 false를 반환시키면 된다.
주어진 문제 해결방법 두가지를 글로 설명했다. 두 알고리즘 중 어떤게 더 효율이 좋을지 알 수 있을까? 알고리즘 성능을 비교하기 위해선 수학적으로 풀어야만 한다. 표기 방법을 사용해 서로 비교할 수 있다면 수학적 규칙을 따른다고 할 수 있다.
위에 작성한 알고리즘을 코드로 풀어 작성해보자.
class FindDuplicates {
/**
* @param {int[]} arr
*/
duplicate1(arr) {
for (let i = 0; i < arr.length; i += 1) {
for (let j = i + 1; j < arr.length; j += 1) {
if (arr[i] === arr[j]) {
return true;
}
}
}
return false;
}
/**
* @param {int[]} arr
*/
duplicate2(arr) {
for (let i = 0; i < arr.length; i += 1) {
if (arr[i] === arr[i + 1]) {
return true;
}
}
return false;
}
}duplicate1은 주어진 두번의 루프를 통해 결과물을 찾고, duplicate2는 한번의 루프를 통해 결과를 찾는다. 이 정보만 사용한다면, 직관적으로 duplicate2가 더 효율적이다. 그럼 얼마만큼 효율적일까? 그건 아직 알 수 없다. 특정 코드가 다른 코드보다 얼마만큼 효율적인지 찾기 위해선, 코드 실행속도를 파악해야 한다.
소요 시간을 활용한 비교
class FindDuplicates {
run1(arr) {
console.time("find duplicate1");
this.duplicate1(arr);
console.timeEnd("find duplicate1");
}
run2(arr) {
console.time("find duplicate2");
this.duplicate2(arr);
console.timeEnd("find duplicate2");
}
...
}
const dup1 = new FindDuplicates();
const dup2 = new FindDuplicates();
console.log("\nN: 1000");
const arr2 = Array.from({ length: 1000 }, (_, i) => i + 1);
dup1.run1(arr2);
dup2.run2(arr2);
console.log("\n\nN: 10000");
const arr3 = Array.from({ length: 10000 }, (_, i) => i + 1);
dup1.run1(arr3);
dup2.run2(arr3);중복 요소를 찾는 코드가 소요한 시간을 출력하는 코드를 작성했다. 그리고 array의 크기가 1,000일때부터 시작하여 100,000까지 소요시간을 계산했다.

실행 결과, duplicate1은 1ms부터 최대 4000ms까지 증가했다. duplicate2는 문제 수가 아무리 늘어나도 1ms대에서 처리가 완료된다.

credit: Josh Hug CS61B
위 데이터는 코드 실행 결과이다. 해결해야 하는 문제의 수 N이 늘어날수록, dup1은 처리속도가 크게 늘어나는 반면, dup2는 처리속도가 비교적 일정적이다. 따라서 dup2가 비용 방면에서 훨씬 효율적인 알고리즘이다.
실행되는데 소요된 시간으로 코드 효율성을 판단하는건 이처럼 직관적이고 쉽다. 하지만 많이 사용되지는 않는 방법이다. 문제의 수 N이 많아지면 코드 실행이 불가능할 수 있기 때문이다. 또한 코드를 실행하는 컴퓨터의 성능과, 알고리즘을 실행하는 프로그래밍 언어의 성능에 따라 측정되는 시간이 바뀔 수 있다. 시간을 측정하는 방식은 변수가 많기 때문에 객관적인 측정방법이 아니다.
코드 효율성: 모델화
따라서 코드가 처리하는 작업을 모델화 하여 효율을 측정할 수 있다. 모델화는 코드가 실행될 때 처리하는 연산작업이 문제의 수에 따라 얼만큼 늘어나는지 계산하는 방법이다. 이전에 작성했던 코드 일부분을 살펴보자.
for (let i = 0; i < arr.length; i += 1) {
for (let j = i + 1; j < arr.length; j += 1) {
if (arr[i] === arr[j]) {
return true;
}
}
}
return false;
코드는 i = 0; 비교 연산자, i += 1, j = i + 1등과 같은 연산 작업들을 하고 있다. 코드를 모델링 하기 위해 사용된 연산 작업들을 테이블에 나열해보자.

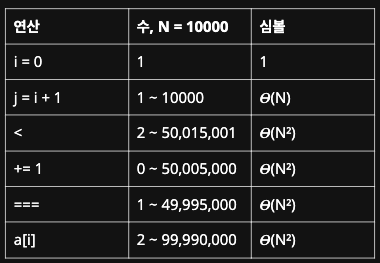
그리고 문제의 수 N이 주어졌을 때, 각 연산이 몇번 실행되는지를 작성해보자. i = 0의 경우, 최초 코드 실행시 단 한번만 실행된다. j = i + 1의 경우, 결과물이 바로 첫번째 루프에서 반환된다면 1회만 실행되고, 가장 나쁜 경우 모든 루프를 다 돌아야 해서 10,000번 실행이 된다. 이런식으로 각 연산이 실행되는 가장 좋은 경우와 가장 나쁜 경우를 작성했다. < 연산자는 2회에서 약 5천만회. += 1는 0회에서 약 5천만 회. ===도 1회에서 5천만 회. 그리고 어레이 접근자는 최대 약 1억회까지 실행된다.
모델링을 통해 각 연산이 몇번 실행되는지 파악할 수 있다. 따라서 코드를 실행하는 기계나 프로그래밍 언어 성능에 종속되지 않고도 코드 효율성을 파악할 수 있다. 하지만, 이 수치들을 계산하는건 어렵다. 또한 연산작업이 총 소요하는 시간을 알 수 없다. 위에 작성했던 모델을 더 효과적으로 표현하기 위해, 실제 계산한 연산실행 수 대신 심볼 N을 활용하기도 한다.

이전에는 정해진 문제 수에 대한 연산 횟수만 계산했다. 심볼 N을 대입하여 문제 수가 변할때, 각 연산이 어떻게 비례해서 증감하는지 모델링이 가능하다.
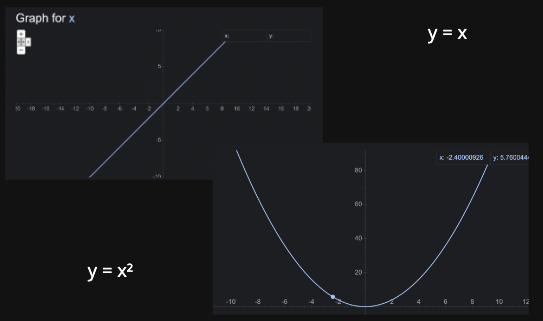
여기서 증감이란, y = x, y = x² 과 같은 그래프를 통해 살펴볼 수 있다. y = x 그래프는 일직선으로 뻗어나간다. y = x² 그래프는 포물선을 그리며 뻗어나간다. 여기서 x 대신 N을 넣으면, 문제 수가 커짐에 따라 처리해야 하는 연산 수가 어떻게 증가하는지 파악할 수 있다.

그럼 심볼을 활용해 두 알고리즘을 비교해보자. N으로 모델링 했을 때, duplicate2는 모든 연산들이 N 수준으로 늘어나고 있다. 반면 duplicate1은 N² 수준으로 늘어나고 있다. 위 그래프를 살펴보았을 때, x는 일직선이고 x²은 포물선을 그렸다. 따라서 문제 수가 늘어난다면, x가 x²보다 적은 연산작업을 실행한다. 더 적은 연산 작업을 처리하기 때문에 속도도 빠를수밖에 없다.

수치로 살펴보면, +=1 작업을 처리할 때 duplicate1은 최대 (N² + N)/2 작업을 처리해야 한다. 반면 duplicate1은 N-1 작업만 처리한다. 문제가 커질수록, duplicate1이 처리하는 연산 수는 duplicate2가 처리하는 연산 수보다 적게 늘어난다. 이 경우를 duplicate1 알고리즘이 더 효과적으로 증가한다고 표현한다.
점근적 행동 - Asymptotic Behavior
점근적 행동이란, 특정 함수가 해결해야 할 문제 N이 커질 때 어떻게 동작하는 지 파악하기 위해 사용된다. 특히 알고리즘과 자료구조를 처음 공부하면 Asymptotic Behavior라는 표현을 많이 보게 된다. 이를 쉽게 이해하기 위해선 그래프를 유용하게 사용한다.

함수 f(x) = 20x² + 7x - 4000는 위 그래프로 표현이 된다. 이 함수가 위 모양대로 그려질 때 가장 중요한 요소는 무엇일까?

물론 -4000도 작지 않은 수이다. 그러나 그래프를 조금 더 축소해본다면, -4000은 수치상 큰 의미를 갖지 않는다.

더 나아가 +7x도 문제가 커지게 되면 큰 의미를 갖지 않게 된다.

마지막으로 20x²에 있는 숫자 20도 큰 의미가 없다. 이와 같이 엄청나게 많은 데이터를 사용하게 되면, 실질적으로 그래프 모양에 영향을 미치는 요소는 제일 높은 차수의 변수이다. 즉, 앞에 달려있던 20, + 4000, + 7x 등은 영향을 미치지 않고, 가장 높은 차수 x²만 영향을 미친다. 변수가 극한에 접근하면서 나타나는 행동을 점근적 행동이라 한다. 이는 알고리즘 효율성을 표현할 때 아주 유용하다.
포물선 vs 일직선
prep 함수는 N개 데이터를 전처리한다. prep1은 2N² 속도로 데이터를 처리하고, prep2는 1000N 속도로 처리한다. 이 경우, 어떤 알고리즘이 더 효과적일까?

단순하게 보면, 2N²가 더 좋아보인다. 1000N보다 그래프가 더 아래에 위치하고 있다. 따라서 문제 수가 적을 때에는 2N²가 1000N보다 처리하는 연산 수가 적다.

하지만, N이 극한으로 커지게 되면 어떨까? 그래프가 어떻게 증가하고 있는지 파악해야 한다. 1000N은 일직선으로 증가하지만, 2N²은 포물선을 그리며 증가하고 있다. 따라서 문제 수가 커질수록 포물선이 늘어나는 비율은 일직선이 늘어나는 비율보다 커진다. 따라서 문제수가 극한에 가까워질수록, 일직선은 증가량이 미미하지만, 포물선은 눈에 띄게 상승한다.

함수를 그래프로 그렸을 때 보이는 점근성 행동을 증가기준, 또는 Order of Growth라고 한다. 알고리즘 분석 시 점근성이 중요한 이유는, 나쁜 점근성을 갖고 있는 경우 문제 해결이 아예 불가능 할 수 있기 때문이다. 위 차트를 보면, 100,000 문제를 처리할 때 N 점근성을 가진 경우 1초도 걸리지 않지만, N²을 가진 경우 3시간이 걸린다. 더 나쁜 경우, 32년이 걸릴 수도 있다.

결과적으로, 이전에 비교했던 알고리즘 점근성을 보자. duplicate1은 N²으로 증가하고 있고, duplicate2는 N으로 증가하고 있다. 따라서 duplicate1이 더 좋은 점근성 행동을 보이기 떄문에 duplicate2보다 효율적인 알고리즘이다.
코드 효율성 표기 방법
Cost Model
duplicate1은 포물선과 같은 함수로 표현을 했고, duplicate2는 직선과 같은 함수로 표현을 했다. 여기서 왜 굳이 ~~와 같은 이라는 표현을 했을까? 이는 함수 성능을 파악하기 위해선 함수를 단순화 시켜야 하기 때문이다. 알고리즘을 비교하기 위해서는, 우선 해당 알고리즘을 대표할 수 있는 연산 작업을 선택해야 한다. 그 외의 연산 작업은 사실 큰 영향을 미치지 않는다. 이는 점근성에서 설명한것처럼, 그래프가 펼쳐지는 모양은 가장 큰 지수가 결정하기 때문이다.

만약 특정 알고리즘이 위와 같은 점근성을 갖고있다면, 이 알고리즘을 대표하는 연산은 > 이다. > 연산이 2N³ 으로 가장 높은 지수를 갖고 있다. 따라서 100N² 나 5000은 해당 알고리즘을 대표하는 연산작업이 아니다.
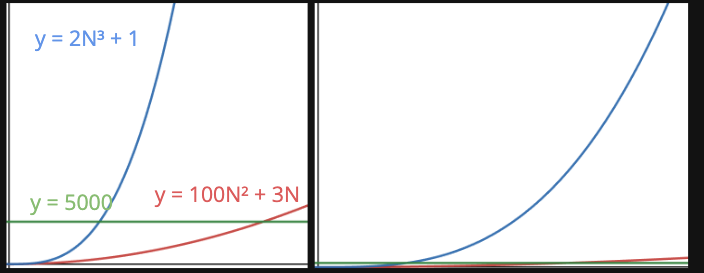
물론 N 수치가 작은 경우, 낮은 차수들도 어느정도 영향을 미친다. 다만, 점근성은 N이 극한으로 가는 경우를 생각한다. 따라서 낮은 차수들은 결국 미미한 영향만 미치게 되어 무시하게 된다.

duplicate1 코드를 다시 살펴보자. 여지껏은 해당 코드를 다음과 같은 심볼로 표현했다. 점근성에서 설명한것처럼, 그래프가 펼쳐지는 모양은 가장 큰 지수가 결정한다. 이 알고리즘 에서 가장 큰 지수는 N²이다. 따라서 이 알고리즘을 대표하는 연산은 아래에 하이라이트 된 네 작업들이다.

이 작업들 중 모든 연산을 대표할 연산 하나를 선택하자. 어차피 네 연산 다 같은 지수를 갖고 있기 때문에 무엇을 선택하든 큰 상관은 없다. 다만 더 쉬운 표현을 위해 +=1 작업을 선택했다. 이렇게 선택된 대표 연산을 cost model이라고 한다.

점근성을 다룰 때 살펴봤듯이, 함수에서 하위 차수에 있는 요소들은 큰 영향을 미치지 않는다. 미적분을 배웠다면, limit을 무제한으로 둔 뒤 행동을 살펴보면 증명할 수 있는 요소이다. 하지만 이건 그래프를 그려보기만 해도 알 수 있어서 굳이 미적분을 몰라도 되니 넘어가도록 하자. 아무튼, 위와 같은 이유로 코스트모델에서 낮은 차수 N은 제거해도 좋다.

그리고 모든 상수들을 제거한다. 상수가 영향을 미칠 수 있지만, 마찬가지 이유로 큰 영향을 미치진 않는다. 따라서 코스트모델이 붙은 상수들은 우리 관심사가 아니다.

결과적으로, duplicate1 알고리즘은 N² 코스트 모델을 갖고 있다.
Big Theta
Big Theta는 여지껏 계산한 작업들을 조금 더 수학적으로 표현하는 방법이다.

예를 들어, Q(N) 함수가 주어졌을 때 증가기준을 위 이미지처럼 표현할 수 있다. 이번에 살펴볼 Big Theta는 수학적으로 복잡해 보이지만, 우리가 여지껏 했던 작업과 똑같다. 다만, 증가기준이 아니라 Big Theta를 활용해 표기하는 것 뿐이다.

여지껏은, 위와 같은 함수들에 대해 증가기준을 우측과 같이 표현했다. 모든 하위차수들을 제거하고, 상수를 제거한 뒤 남은 가장 높은 차수가 결국 증가기준이였다.

이를 Big Theta로 표현한다면, 좌측에 있는 예시와 같이 표현이 가능하다.

Big Theta를 수학적 공식으로 표기하면 위 설명과 같다. 뜻을 설명하자면, 어떤 함수 R(N)이 f(N) * k1과 f(N) * k2 사이에 위치하는 경우, R(N)은 f(N)의 Big Theta에 속한다고 표현한다. 글로 설명을 보면 난해하니 그래프로 살펴보자.

위 그래프에서, R(N)은 빨간 선이다. 그리고 빨간 선이 검정 선들 (k1 * f(n)과 k2 * f(n)) 사이에 놓여있기 때문에 R(N)은 f(N)의 Big Theta에 속한다고 표현할 수 있다.
따라서 Big Theta를 사용한다고 런타임 분석이 딱히 바뀌지는 않는다. 다만 특정 연산작업이 가진 최악의 경우를 파악할 때 증가기준을 Big Theta로 표기할 뿐이다.